Navigation innerhalb: Archiv-Chronologie
21. April 2026Archiviert
Rendering Optimierungen
Ein System mit einer handelsüblichen APU (Accelerated Processing Unit) verfügt über keine dedizierte Grafikkarte mit eigenem, ultraschnellem VRAM. Stattdessen teilt sich der Chip den normalen Arbeitsspeicher (RAM) zwischen der CPU und der integrierten GPU. Die größte Leistungsbremse in einem solchen System ist nicht mangelnde Rechenkraft, sondern die Speicherbandbreite – also die Frage, wie schnell Daten zwischen RAM, CPU und GPU hin- und hergeschoben werden können.
Um darauf 3000 unabhängige 3D-Agenten und 30 parallele Texteditoren bei flüssigen 60 FPS zu berechnen, reicht "normales" Programmieren nicht aus. Es erfordert Mechanical Sympathy: Die Software-Architektur muss exakt verstehen, wie die Hardware physisch arbeitet (Cache-Hierarchien, Parallelität, Draw-Call-Limits) und ihre Daten entsprechend aufbereiten.
Im Folgenden werden die wichtigsten Mechanismen und ihre genaue Funktionsweise im Detail erklärt.
1. Datenorientiertes Design (Data-Oriented Design)
In der klassischen objektorientierten Programmierung (OOP) ist jedes Objekt ein eigenständiges Konstrukt im Speicher, oft verknüpft durch Zeiger (Pointer).
Das Problem: Wenn die CPU durch 3000 Objekte iteriert, muss sie ständig an völlig unterschiedliche Stellen im RAM springen, um die Daten zu finden. Da der RAM im Vergleich zum kleinen, aber extrem schnellen CPU-Cache sehr langsam ist, muss die CPU warten. Das nennt man einen Cache Miss.
Die Lösung: Die Engine nutzt stattdessen flache, durchgehende Arrays (im Code: Array<WorldObject>).
- Wie funktioniert das genau? Alle Instanzen der Spielwelt liegen wie Perlen auf einer Schnur direkt hintereinander in einem einzigen, großen Speicherblock. Wenn die CPU das erste Objekt in ihren L1-Cache lädt, lädt sie (aufgrund der Hardware-Architektur) automatisch die nächsten Dutzend Objekte direkt mit. Die CPU kann diese Datenblöcke nun linear und ohne Wartezeiten "durchrattern". Der Overhead durch Speicherzugriffszeiten wird dadurch massiv minimiert.
2. Parallelisierung und Chunking (Arbeitspakete)
Um 3000 Objekte in 16 Millisekunden (für 60 FPS) zu berechnen, muss die Arbeit auf die verfügbaren Kerne und Threads der APU verteilt werden.
Das Problem: Das ständige Erstellen und Zerstören von Threads kostet das Betriebssystem enorm viel Zeit. Wenn mehrere Threads zudem auf dieselben Daten zugreifen wollen, müssen sie sich gegenseitig blockieren (durch sogenannte Mutex-Locks), was zu Staus führt.
Die Lösung: Ein statisches Thread-Pool-Modell mit "Chunking".
- Wie funktioniert das genau? Beim Start des Programms werden feste "Worker-Threads" gestartet, die dauerhaft im Hintergrund wach bleiben. Die 3000 Objekte werden in feste Blöcke (Chunks) von z. B. 256 Objekten aufgeteilt. Thread 1 bekommt die Objekte 0-255, Thread 2 die Objekte 256-511. Da das Array (siehe Punkt 1) flach ist, weiß jeder Thread genau, wo sein Bereich anfängt und aufhört. Da kein Thread in den Bereich eines anderen schreibt, sind keine Locks notwendig. Die Threads arbeiten völlig unabhängig voneinander und rufen erst wieder ein neues Paket ab, wenn sie fertig sind.
3. Reduktion algorithmischer Komplexität (O(1) Lookups)
Die Engine muss ständig Fragen beantworten wie: An welcher absoluten Koordinate befindet sich Objekt B, wenn es an Objekt A andocken (Snapping) soll?
Das Problem: Wenn 3000 Objekte bei jedem Frame das gesamte Array durchsuchen müssen, um ihre Nachbarn zu finden, skaliert das exponentiell (O(N²)). Bei 3000 Objekten wären das im schlimmsten Fall 9 Millionen Überprüfungen pro Frame – ein sofortiger Einbruch der Framerate.
Die Lösung: Hash-Maps für sofortige Zugriffe.
- Wie funktioniert das genau? Zu Beginn jedes Frames baut die Engine einmalig eine Tabelle (Hash-Map) auf, die Objekt-IDs (z.B. ID #42) auf den genauen Index im Array (z.B. Platz #15) abbildet. Ein Lookup dauert nun konstante Zeit (O(1)) – es ist, als würde man in einem gut sortierten Telefonbuch direkt den Namen aufschlagen, anstatt jede Seite einzeln zu lesen. Die Traversierung des Szenengraphen ist dadurch extrem leichtgewichtig.
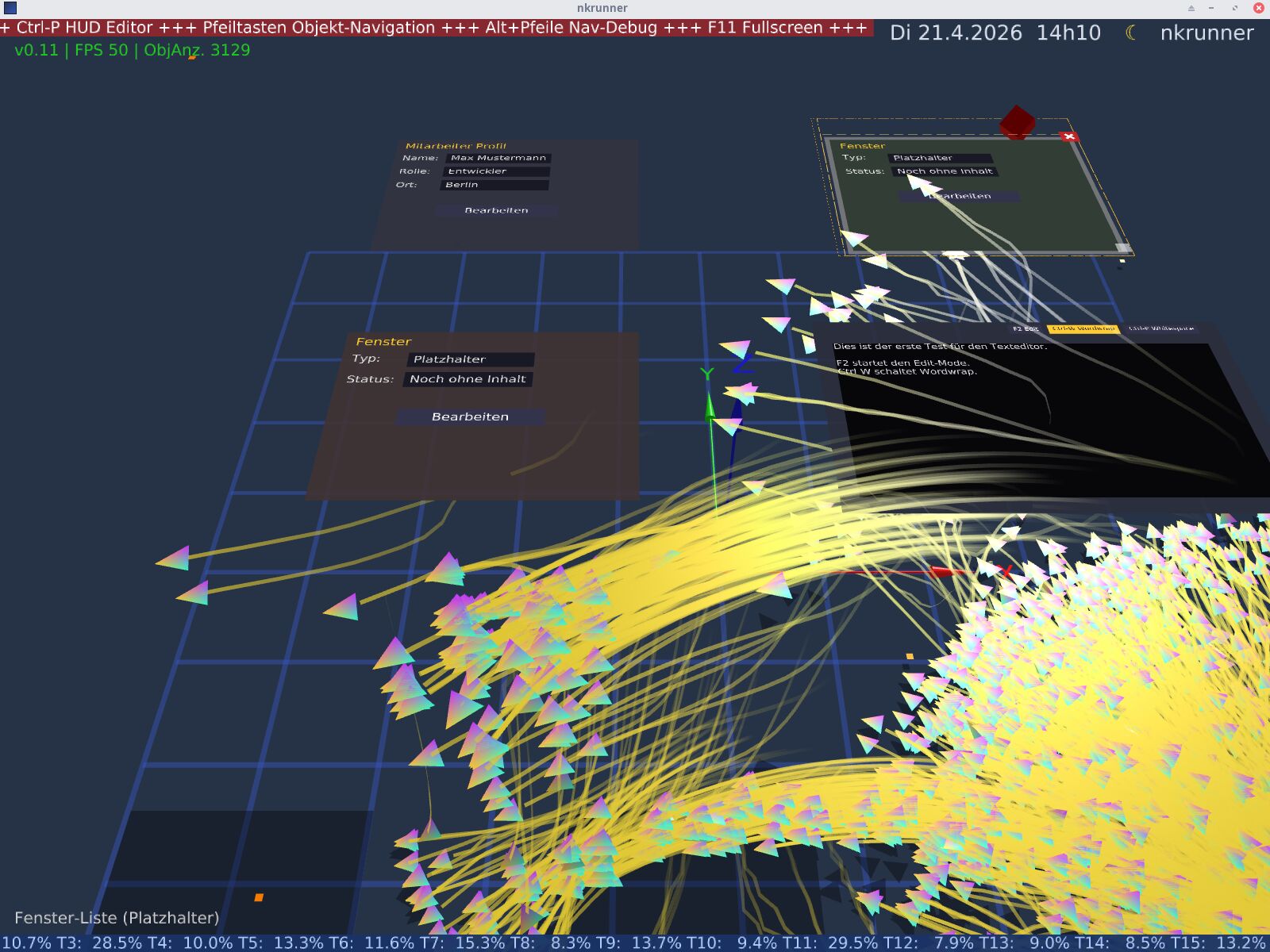 Abb 1: Frames und animierte Objekte
Abb 1: Frames und animierte Objekte
4. Zustandsbasiertes UI-Caching
Text-Rendering und UI-Layouting (wie in den 30 virtuellen Code-Editoren) sind extrem teuer. Für jeden Buchstaben muss berechnet werden: Wie breit ist das Zeichen? Passt das nächste Wort noch in die Zeile oder brauche ich einen Zeilenumbruch?
Das Problem: Diese Berechnungen für zehntausende Zeichen jeden Frame neu durchzuführen, würde die CPU überlasten.
Die Lösung: Zwischenspeichern (Caching) der finalen Zeichenbefehle.
- Wie funktioniert das genau? Aus den Parametern eines Fensters (Breite, Höhe, Textlänge, Scroll-Position) wird ein Fingerabdruck (Hash-Key) erstellt. Bevor die Engine den Text anordnet, prüft sie: Hat sich dieser Fingerabdruck im Vergleich zum letzten Frame geändert?
- Nein: Die CPU überspringt die gesamte Logik und kopiert einfach die fertigen Geometriedaten (die Dreiecke der Buchstaben) des letzten Frames.
- Ja (z.B. weil der Nutzer scrollt oder tippt): Nur dieses eine spezifische Fenster wird neu berechnet.
5. CPU-Batching und Render-Graphen
Hier greift die wichtigste Optimierung für die Grafikkarte (GPU).
Das Problem: Eine GPU ist ein Monster darin, Millionen von Dreiecken zu zeichnen. Sie ist aber furchtbar schlecht darin, Befehle entgegenzunehmen. Jeder Befehl der CPU an die GPU ("Zeichne dieses Objekt", genannt Draw Call) hat enormen Overhead im Grafiktreiber. Wenn die CPU 3000 Mal ruft: "Zeichne ein Dreieck!", verbringt das System 90% der Zeit mit dem Kommunikation und nur 10% mit dem eigentlichen Zeichnen.
Die Lösung: Geometrie-Batching und Sortierung.
- Wie funktioniert das genau? Die Worker-Threads (aus Punkt 2) berechnen die 3D-Koordinaten aller 3000 Objekte fertig auf der CPU und schaufeln die Eckpunkte (Vertices) in ein einziges, riesiges Array im Speicher. Der "Render-Graph" sortiert diese Daten dann nach dem verwendeten Shader oder Material, um GPU-Zustandswechsel zu minimieren. Am Ende schickt die CPU statt 3000 Draw Calls nur eine Handvoll großer Pakete an die GPU: "Hier ist ein Array mit 9000 Dreiecken, male sie alle in einem Rutsch mit demselben Shader." Die GPU kann diese parallel verarbeiten, ohne auf neue Befehle der CPU warten zu müssen.
6. Vektorbasiertes Text-Rendering (SDF - Signed Distance Fields)
Auch das Darstellen von Text muss auf einer APU bandbreitenschonend ablaufen.
Das Problem: Traditionell rendert man Schriften, indem man ein Bild (Textur) mit dem Alphabet in einer bestimmten Auflösung (z.B. Schriftgröße 12) in den Speicher lädt. Will man den Text heranzoomen, wird er unscharf. Braucht man ihn in Größe 48, muss man eine neue, riesige Textur laden. Das verbraucht extrem viel VRAM und Bandbreite.
Die Lösung: SDF (Signed Distance Fields).
- Wie funktioniert das genau? Die Engine nutzt eine spezielle, sehr kleine Textur. Diese speichert nicht die Farben der Buchstaben, sondern mathematische Distanzwerte. Ein Pixel in dieser Textur sagt nur: "Ich bin 3 Pixel vom Rand des Buchstabens entfernt". Im Shader-Programm auf der GPU passiert dann die Magie: Wenn das GPU-Programm gezeichnet wird, prüft es nur: Ist die Distanz kleiner als 0? Dann bin ich innerhalb des Buchstabens und male den Pixel schwarz. Ist sie größer? Dann bin ich außerhalb und male transparent.
Der Effekt: Mit einer einzigen, extrem speichersparenden Textur lässt sich Text stufenlos, gestochen scharf und in jeder beliebigen Größe (sogar in 3D rotiert) darstellen, ohne dass die APU-Bandbreite belastet wird.
7. Profiling und Telemetrie: Der Nachweis der Optimierung
Um diese ehrgeizigen Ziele zu erreichen und Bottlenecks gezielt zu eliminieren, verfügt die Engine über ein integriertes, hierarchisches Profiling-System sowie Echtzeit-CPU-Telemetrie.
Gleichmäßige CPU-Auslastung (Load Balancing) Die CPU-Last (Load Distribution) wirklich gleichmäßig über alle logischen Kerne zu verteilen, war einer der größten Entwicklungsaufwände innerhalb der Architektur. Ohne sauberes Chunking und intelligentes Multithreading würde der Haupt-Thread bei nahezu 100% blockieren, während die übrigen Kerne im Leerlauf verharren. Die folgende Telemetrie beweist, wie die Arbeitspakete im laufenden Betrieb erfolgreich auf alle logischen Threads (T0 bis T15) des Systems verteilt werden. Einige Ausreißer nach oben (wie T2 und T10) sind erwartet, da hier der Main-Thread das finale Render-Submission an die Grafik-API vornimmt:
=== CPU LOAD DISTRIBUTION (10-Sek-Avg) ===
Zeigt die Auslastung der logischen Prozessorkerne im System.
Core | Avg Load (%) | Last Load (%)
------------------------------------------
T0 | 12.4 % | 19.4 %
T1 | 9.3 % | 9.0 %
T2 | 28.5 % | 39.6 %
T3 | 8.1 % | 6.8 %
T4 | 10.0 % | 10.9 %
T5 | 11.4 % | 8.9 %
T6 | 11.2 % | 12.6 %
T7 | 7.5 % | 6.9 %
T8 | 19.0 % | 31.7 %
T9 | 6.1 % | 5.9 %
T10 | 42.5 % | 22.5 %
T11 | 9.5 % | 9.9 %
T12 | 8.2 % | 5.9 %
T13 | 6.9 % | 8.7 %
T14 | 9.2 % | 10.7 %
T15 | 5.8 % | 6.9 %
Hierarchisches Performance-Profil
Der eingebaute Profiler misst die exakten Ausführungszeiten auf die Millisekunde genau. Hier zeigt sich die finale Wirksamkeit des datenorientierten Designs und des dynamischen CPU-Batchings. Die Logikberechnung und Geometrie-Aufbereitung von tausenden Objekten (z.B. Logic_Triangles, SceneBatched_Triangles) ist dank Cache-Hit-Optimierungen auf absolute Minimalwerte im niedrigen Millisekunden-Bereich geschrumpft:
=== PERFORMANCE CALL TREE ===
Einheit: Millisekunden (ms)
Call Graph | Calls | Total (ms) | Avg (ms) | Max (ms)
---------------------------------------------------------------------------------------------------------------------
├─ 1 FrameTotal | 598 | 648.24 | 1.0840 | 2.22
│ ├─ 1.1 Render_MainScreenPass | 598 | 207.07 | 0.3463 | 0.61
│ │ ├─ 1.1.1 DrawScene_Main | 598 | 126.34 | 0.2113 | 0.41
│ │ │ ├─ 1.1.1.1 DrawScene_NormalPass | 598 | 89.62 | 0.1499 | 0.34
│ │ │ │ ├─ 1.1.1.1.1 SceneBatched_VirtualWindows | 598 | 38.90 | 0.0650 | 0.14
│ │ │ │ │ └─ 1.1.1.1.1.1 VW_DrawObject | 2392 | 34.93 | 0.0146 | 0.07
│ │ │ │ │ ├─ 1.1.1.1.1.1.1 VW_DrawMain | 2392 | 16.63 | 0.0070 | 0.03
│ │ │ │ │ └─ 1.1.1.1.1.1.2 VW_WindowControls | 2395 | 0.66 | 0.0003 | 0.01
│ │ │ │ ├─ 1.1.1.1.2 SceneBatched_ExecuteGraph | 598 | 30.83 | 0.0515 | 0.21
│ │ │ │ │ ├─ 1.1.1.1.2.1 ExecuteGraph_NativeDraws | 598 | 23.66 | 0.0396 | 0.19
│ │ │ │ │ └─ 1.1.1.1.2.2 ExecuteGraph_Sort | 598 | 4.94 | 0.0083 | 0.03
│ │ │ │ ├─ 1.1.1.1.3 SceneBatched_BoundsAndLabels | 598 | 4.83 | 0.0081 | 0.06
│ │ │ │ ├─ 1.1.1.1.4 SceneBatched_PushGlobalBatch | 598 | 2.63 | 0.0044 | 0.04
│ │ │ │ ├─ 1.1.1.1.5 SceneBatched_WanderingPoints | 598 | 1.74 | 0.0029 | 0.01
│ │ │ │ ├─ 1.1.1.1.6 SceneBatched_Triangles | 598 | 1.42 | 0.0024 | 0.01
│ │ │ │ └─ 1.1.1.1.7 SceneBatched_RedCubes | 598 | 0.72 | 0.0012 | 0.01
│ │ │ ├─ 1.1.1.2 DrawScene_ShadowPass | 598 | 31.77 | 0.0531 | 0.11
│ │ │ │ ├─ 1.1.1.2.1 SceneBatched_ExecuteGraph | 598 | 11.87 | 0.0199 | 0.05
│ │ │ │ │ ├─ 1.1.1.2.1.1 ExecuteGraph_NativeDraws | 598 | 8.62 | 0.0144 | 0.04
│ │ │ │ │ └─ 1.1.1.2.1.2 ExecuteGraph_Sort | 598 | 1.10 | 0.0018 | 0.01
│ │ │ │ ├─ 1.1.1.2.2 SceneBatched_VirtualWindows | 598 | 7.21 | 0.0121 | 0.05
│ │ │ │ │ └─ 1.1.1.2.2.1 VW_DrawObject | 2392 | 2.83 | 0.0012 | 0.01
│ │ │ │ ├─ 1.1.1.2.3 SceneBatched_WanderingPoints | 598 | 2.00 | 0.0033 | 0.01
│ │ │ │ ├─ 1.1.1.2.4 SceneBatched_RedCubes | 598 | 0.99 | 0.0017 | 0.01
│ │ │ │ ├─ 1.1.1.2.5 SceneBatched_Triangles | 598 | 0.62 | 0.0010 | 0.01
│ │ │ │ ├─ 1.1.1.2.6 SceneBatched_BoundsAndLabels | 598 | 0.38 | 0.0006 | 0.00
│ │ │ │ └─ 1.1.1.2.7 SceneBatched_PushGlobalBatch | 598 | 0.18 | 0.0003 | 0.00
│ │ │ ├─ 1.1.1.3 DrawScene_DebugOverlays | 598 | 0.22 | 0.0004 | 0.05
│ │ │ └─ 1.1.1.4 DrawScene_AnchorMarkers | 598 | 0.08 | 0.0001 | 0.00
│ │ ├─ 1.1.2 Graphics_Commit | 598 | 1.32 | 0.0022 | 0.01
│ │ └─ 1.1.3 Graphics_EndPass | 598 | 0.82 | 0.0014 | 0.01
│ ├─ 1.2 Render_OffscreenPass_Picking | 598 | 155.31 | 0.2597 | 0.74
│ │ ├─ 1.2.1 DrawScene_PickingPass | 598 | 101.85 | 0.1703 | 0.66
│ │ │ ├─ 1.2.1.1 SceneBatched_ExecuteGraph | 598 | 35.89 | 0.0600 | 0.14
│ │ │ │ ├─ 1.2.1.1.1 ExecuteGraph_NativeDraws | 598 | 26.95 | 0.0451 | 0.12
│ │ │ │ └─ 1.2.1.1.2 ExecuteGraph_Sort | 598 | 6.10 | 0.0102 | 0.06
│ │ │ ├─ 1.2.1.2 SceneBatched_VirtualWindows | 598 | 28.54 | 0.0477 | 0.10
│ │ │ │ └─ 1.2.1.2.1 VW_DrawObject | 2392 | 23.94 | 0.0100 | 0.05
│ │ │ │ ├─ 1.2.1.2.1.1 VW_DrawPicking | 2392 | 6.55 | 0.0027 | 0.02
│ │ │ │ └─ 1.2.1.2.1.2 VW_WindowControls | 2392 | 3.83 | 0.0016 | 0.02
│ │ │ ├─ 1.2.1.3 SceneBatched_WanderingPoints | 598 | 3.71 | 0.0062 | 0.03
│ │ │ ├─ 1.2.1.4 SceneBatched_RedCubes | 598 | 2.43 | 0.0041 | 0.02
│ │ │ ├─ 1.2.1.5 SceneBatched_BoundsAndLabels | 598 | 2.40 | 0.0040 | 0.02
│ │ │ ├─ 1.2.1.6 SceneBatched_Triangles | 598 | 1.69 | 0.0028 | 0.02
│ │ │ └─ 1.2.1.7 SceneBatched_PushGlobalBatch | 598 | 0.45 | 0.0008 | 0.01
│ │ └─ 1.2.2 Graphics_EndPass | 598 | 2.00 | 0.0034 | 0.02
│ ├─ 1.3 Update_World_Logic | 598 | 106.61 | 0.1783 | 0.47
│ │ ├─ 1.3.1 Logic_Triangles | 598 | 72.97 | 0.1220 | 0.18
│ │ ├─ 1.3.2 Logic_BuildGrid | 598 | 5.57 | 0.0093 | 0.04
│ │ │ ├─ 1.3.2.1 Grid_Gather | 598 | 0.76 | 0.0013 | 0.00
│ │ │ ├─ 1.3.2.2 Grid_FillSlots | 598 | 0.24 | 0.0004 | 0.00
│ │ │ └─ 1.3.2.3 Grid_Sort | 598 | 0.19 | 0.0003 | 0.00
│ │ ├─ 1.3.3 Logic_Wandering | 598 | 0.45 | 0.0007 | 0.01
│ │ └─ 1.3.4 Logic_RedCubes | 598 | 0.39 | 0.0006 | 0.01
│ ├─ 1.4 Build_SceneLayoutCache | 598 | 16.15 | 0.0270 | 0.08
│ │ ├─ 1.4.1 LayoutCache_ExecuteWorkers | 598 | 8.27 | 0.0138 | 0.06
│ │ ├─ 1.4.2 LayoutCache_TraverseGraph | 598 | 4.64 | 0.0078 | 0.04
│ │ └─ 1.4.3 LayoutCache_Init | 598 | 0.28 | 0.0005 | 0.00
│ ├─ 1.5 Update_UI_Layouts | 598 | 3.94 | 0.0066 | 0.02
│ ├─ 1.6 Update_TextWindow_Metrics | 598 | 2.03 | 0.0034 | 0.01
│ │ └─ 1.6.1 TextDoc_EnsureLayout | 598 | 0.18 | 0.0003 | 0.00
│ └─ 1.7 Update_OffscreenPass_Preparation | 598 | 0.16 | 0.0003 | 0.00
└─ 2 TextDoc_EnsureLayout | 223 | 0.02 | 0.0001 | 0.00
--- Log-Ende ---
Fazit
Die flüssige Performance der Engine auf einer APU resultiert nicht aus roher Gewalt, sondern aus der strikten Vermeidung von Flaschenhälsen.
- Die CPU bereitet Daten in flachen Arrays ohne Umwege auf (DOD).
- Alle Kerne arbeiten gleichzeitig und balancieren die Last perfekt aus, ohne aufeinander zu warten (Chunking & Load Balancing).
- Schwerfällige Berechnungen (wie Text-Layouts) werden nur gemacht, wenn sich wirklich etwas ändert (Caching).
- Die GPU wird nicht mit Mikro-Befehlen genervt, sondern bekommt massive Datenpakete am Stück (Batching).
- Speicher wird durch smarte Mathematik (SDF-Schriften) geschont.
Weiteres
Navigation innerhalb: Archiv-Chronologie