Navigation innerhalb: Artikelchronologie
25. April 2026
Architektur-Notizen: O(1)-Zugriffe, Worker-Threads und GPU-Batching
In den vergangenen Devlogs ging es oft darum, viele Objekte gleichzeitig darzustellen. Eine ebenso wichtige Anforderung ist jedoch die Interaktion mit diesen Datenmengen.
Wenn man in einer voll ausgelasteten Szene tausende Objekte gleichzeitig selektiert, ändern sich die Anforderungen an die Architektur. Plötzlich müssen für jedes einzelne Objekt zusätzliche Selektionsrahmen berechnet, Schatten-Geometrien aktualisiert und Bewegungsschweife (Trails) gezeichnet werden. Die Menge der zu berechnenden Daten vervielfacht sich schlagartig.
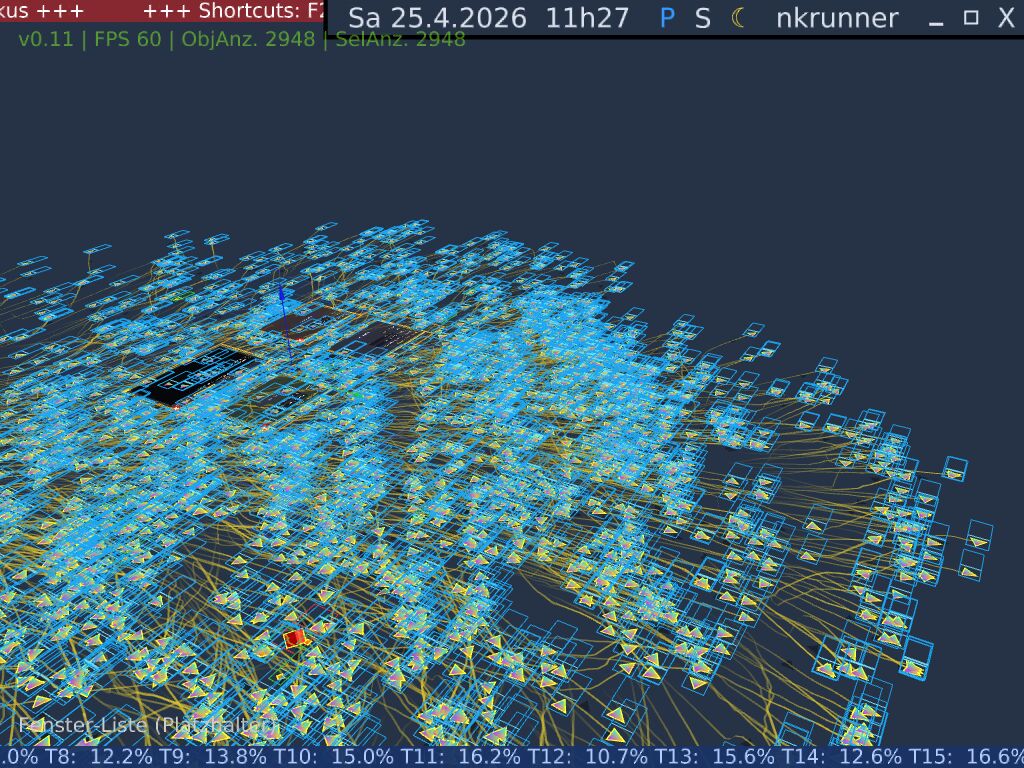 Abb 1: Die Engine bei der gleichzeitigen Selektion und Interaktion mit mehreren tausend Objekten.
Abb 1: Die Engine bei der gleichzeitigen Selektion und Interaktion mit mehreren tausend Objekten.
Vermeidung von O(N²)-Suchen im Szenengraphen
Die Geometrie-Berechnung basiert auf einem hierarchischen Szenengraphen. Wenn nun tausende Objekte pro Frame ihren finalen Zustand für das Rendering berechnen wollen, müssen sie ihre Position im Graph verifizieren und die Transformationen ihrer Elternelemente übernehmen.
Bei naiver Implementierung führt dies zu einer linearen Suche: Für jedes Objekt im Baum muss das zugehörige Datenpaket im flachen Speicher-Array gefunden werden. Bei 3000 Objekten resultiert das in Millionen von linearen Vergleichen auf dem Main-Thread – ein klassischer O(N²)-Flaschenhals.
Exkurs: Was bedeuten O(N²) und O(1)?
In der Softwareentwicklung nutzt man die sogenannte "Big-O-Notation", um zu beschreiben, wie der Rechenaufwand mit wachsender Datenmenge (N) skaliert.
- O(N²) (quadratisches Wachstum): Wenn man 3000 Objekte hat und jedes Objekt im schlimmsten Fall alle anderen 3000 Objekte durchsuchen muss, entstehen 3000 × 3000 = 9 Millionen Einzelschritte. Verdoppelt sich die Objektanzahl, vervierfacht sich die Rechenzeit. Das zwingt ab einer gewissen Menge jedes System in die Knie.
- O(1) (konstante Zeit): Der Zugriff dauert immer exakt gleich lang – egal, ob es 10 oder 10 Millionen Objekte gibt. Das System muss nicht suchen, sondern kann die Position im Speicher durch eine mathematische Formel (Hashing) sofort ableiten.
Die Lösung bestand darin, die Traversierungslogik strikt auf konstante Zugriffszeiten (O(1)) umzustellen. Zu Beginn der Render-Vorbereitung wird nun eine Hash-Struktur aufgebaut, die Objekt-IDs direkt auf ihre physischen Speicherindizes abbildet. Die Traversierung des Graphen erfolgt anschließend als reiner, indexbasierter Durchlauf ohne jegliche Suchoperationen. Die CPU-Zeit für diesen Schritt schrumpfte dadurch vom messbaren Millisekundenbereich auf wenige Mikrosekunden.
Nebenläufige Geometrie-Generierung (Lock-free)
Visuelle Indikatoren wie Selektionsrahmen (Outlines), Text-Labels und Hover-Effekte summieren sich bei großen Mengen auf. Jeder Rahmen besteht aus mehreren Dreiecken, die basierend auf Zoomstufe und Kameraperspektive berechnet werden müssen.
Anstatt diese grafischen Elemente sequentiell im Haupt-Thread zu generieren, übernimmt dies nun das datenorientierte Worker-System. Während der Main-Thread noch andere Aufgaben erledigt, bereiten die Hintergrund-Kerne des Prozessors die Geometriedaten parallel vor.
Exkurs: Threads, Mutex und Lock-free Programmierung
- Threads sind Ausführungsstränge in einem Prozessor. Der Main-Thread ist quasi der Dirigent, während Worker-Threads fleißige Helfer im Hintergrund sind, die gleichzeitig auf anderen Prozessorkernen arbeiten.
- Mutex (Mutual Exclusion) / Locks: Wenn mehrere Threads gleichzeitig in denselben Arbeitsspeicher schreiben wollen, entsteht Datenmüll. Um das zu verhindern, nutzt man "Locks" (Schlösser) oder "Mutexe" (gegenseitiger Ausschluss): Ein Thread sperrt einen Speicherbereich ab, arbeitet darin, und gibt ihn wieder frei. Der gravierende Nachteil: Alle anderen Threads müssen in dieser Zeit warten (Blockade). Die Parallelität wird künstlich ausgebremst.
- Lock-free (schlossfrei): Eine Architektur, die Ampeln und Schlösser überflüssig macht. Wie funktioniert das ohne Chaos? Meistens durch strikte Aufteilung oder Hardware-Tricks. Eine Methode ist die Speicher-Partitionierung: Wenn man einen großen leeren Schrank hat, streiten sich die Threads nicht um den nächsten freien Platz, sondern jeder bekommt vorab feste Regalböden zugewiesen. Jeder räumt seine Daten stur in sein eigenes Fach. Da sich die Wege nie kreuzen, muss niemand warten. Eine andere Methode sind atomare Operationen: Hierbei garantiert der Prozessor auf Hardware-Ebene, dass ein Rechenschritt (z.B. das Hochzählen eines Zählers) so winzig und unteilbar ist, dass kein anderer Thread dazwischenfunken kann. Beide Methoden erlauben es, dass alle Threads jederzeit ungestört und konfliktfrei arbeiten.
Der entscheidende Punkt hierbei: Unsere Architektur arbeitet bei der Geometrie-Generierung exakt nach dem ersten Prinzip der Speicher-Partitionierung. Vor dem Start der Worker-Threads berechnet der Main-Thread vorab, wie viele Vertices jedes Objekt generieren wird. Anschließend weist er jedem Task einen präzisen, exklusiven Speicher-Offset (seinen eigenen Regalbereich) in einem riesigen, vorallokierten Array zu. Die Worker können so gleichzeitig ihre Ergebnisse in denselben globalen Puffer schreiben, ohne sich jemals in die Quere zu kommen oder durch Mutexes blockiert zu werden.
Striktes Draw-Call-Batching
Die Vorbereitung auf der CPU ist nur ein Teil der Aufgabe; die Daten müssen auch effizient an die Grafik-API (wie OpenGL oder Vulkan) übergeben werden.
Exkurs: Draw Calls und Batching
Ein Draw Call ist ein Aufruf der CPU an die Grafikkarte (GPU), etwas Bestimmtes zu zeichnen. Die Kommunikation zwischen diesen beiden Prozessoren (über den Grafiktreiber) ist jedoch schwerfällig. Wenn die CPU 3000 Mal ruft: "Zeichne dieses Dreieck!", verbringt das System fast die gesamte Zeit nur mit dem Senden der Befehle. Batching (Bündelung) bedeutet, all diese Objekte in ein einziges, riesiges Paket zu stecken und nur einen einzigen Draw Call zu feuern: "Hier sind 9000 Dreiecke, zeichne sie alle auf einmal!"
Nehmen wir die Bewegungsschweife (Trails) der Agenten: 3000 Agenten bedeuten 3000 Schweife, die aus teils transparenten Polygonen bestehen. Würde man für jeden Schweif einen eigenen Zeichenbefehl an die GPU senden, entstünde ein massiver Overhead. Die CPU verbringt dann mehr Zeit mit dem Kommunizieren des Befehls als die GPU mit dem eigentlichen Rechnen.
Die Lösung hier ist konsequentes Batching: Anstatt für jeden Trail einen zusammenhängenden Pfad (TriangleStrip) zu rendern, wurde die Geometrie so umgebaut, dass alle Trails als einfache, unzusammenhängende Dreiecke definiert werden. Dadurch können die Worker-Threads alle 3000 Schweife in einem einzigen, großen Vertex-Array (Buffer) zusammenfassen. Anstatt tausende Einzelbefehle zu senden, übergibt die Engine der Grafikkarte nun ein einziges, massives Datenpaket mit dem Hinweis, alles mit demselben Shader in einem Rutsch zu verarbeiten.
Fazit
Durch die Kombination aus konstanter Zugriffskomplexität, paralleler, exakt vorausberechneter Speichernutzung und dem radikalen Bündeln von GPU-Befehlen skaliert das System unter Last nun deutlich berechenbarer. Auch bei die Interaktion mit sehr großen Objektmengen bleibt die Benutzeroberfläche verlässlich flüssig.
Weiteres
Navigation innerhalb: Artikelchronologie